Most content about AI model predictions is not going to age well given how quickly the frontier is moving on what is possible these days. Yet, I find it useful to write such articles as they form the basis of the ongoing conversations about how those models are going to impact all of us in the tech industry.
After my recent trials with vibe coding, I wanted to push the experiment further and apply second-order thinking to project what software engineering will look and feel like in a future in which every software engineer is “augmented” with LLMs.
When you think about it, asking LLMs to write code is not so far from the experience that product managers have today with human software engineers. Most product managers are not technical enough to verify that the products built by software engineers are accurate, correct, and secure. To them, the software is a black box, and they have to trust that the software engineers understood the user stories, and that the QA engineers wrote the right set of tests. This is pretty much what vibe coding is all about, except one asks an LLM to write code instead of a human.
And of course, a product manager might notice bugs or issues, which are logged as tickets for the team to look after. This is similar to the process one has with an LLM, by inputting error logs into the model or asking it to make changes, or even with agentic AI systems that detect error messages and automatically pipe them into additional LLM iterations until the code compiles and the requirements are met.
Software engineering will move away from writing code using programming languages to writing PRDs and acceptance tests, what I call “requirements-as-code.” This is because if you are able to describe your requirements with enough context and details, and if you can correctly describe the expected behaviors to test, then the AI models will be able to both build what you want, and deterministically test all assumptions to guarantee that the code is accurate and correct.
It does not matter what’s in the code as long as you can guarantee that its outputs are what you expect for a given set of inputs. And it might not be entirely correct all the time, just like software written by humans, but if the guarantees are met 99.99% of the time, then they are correct enough to meet commercial standards and be shipped to production.
Just like infrastructure-as-code became a thing over the past decade, we are going to see requirements-as-code becoming the new thing, with new industry standards being created to describe PRDs in a clean and maintainable way for LLM inputting, and those PRDs will be stored with version control repositories to track changes.
Now you might ask, why would we need requirements when we have the source code, can’t we just use the code as requirements? Yes and no.
Yes, ultimately the code can act as your requirements, but also no, because if you rely on the code, then you’re still thinking like a software engineer of the year 2025.
Remember, this is already the future, we’re in the year 2030, and most software is now a black box, just like assembly code is an alien language to most software engineers. Having the source code isn’t particularly useful if you can’t read code so well, what you want is a set of requirement in a natural language, so that as a human, you can understand what is present or missing in the expected behaviors, and so you can make adjustments easily if needed.
Those requirements will be separated into categories, like functional requirements, UX/UI design requirements, data model requirements, and security requirements.
Until now, vibe coding meant endless back‑and‑forth with an AI model. Agentic systems remove that friction: they iterate in a closed loop until the code meets every requirement and clears all acceptance tests, without the need for human intervention. You could even have multimodal AI models perform end-to-end testing from the final consumer’s perspective.
Traditional tooling like package managers and CI/CD pipelines will collapse into one “Regenerate and Validate” button that triggers everything, from architecture generation down to final QA testing.
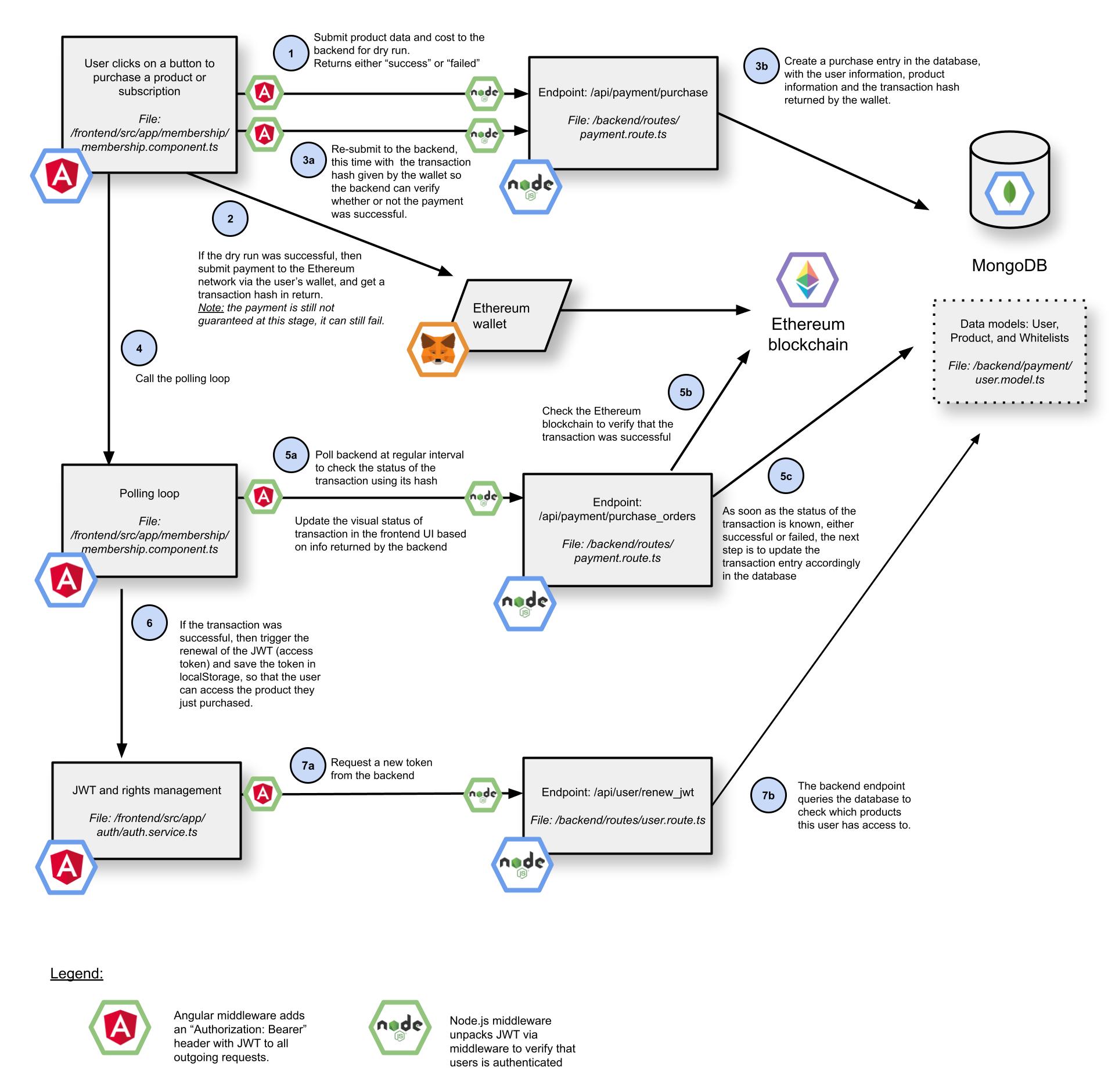
Below is a simplified diagram that illustrates what the process of writing software will become in the near future. As a human operator, you will write requirements and tests, and then everything else will be a black box.

The Main Implications of LLMs for Software Engineering
Based on the above, it’s now only a matter of a few years until a high percentage of all human-driven programming goes away. I spent some time projecting into a second-order thinking what are the main implications I’m forecasting. I had a hard time organizing them holistically so instead I’m presenting them individually in the sections below.